Вынужденный переход на удаленный режим функционирования стал для многих компаний стимулом попробовать новые форматы работы. Пик спроса в ИТ пришелся на виртуальное рабочее пространство. Понадобилось оно и нашим клиентам. По традиции мы решили сначала протестировать такое решение на себе, прежде чем предлагать его клиентам. Попробовав несколько опций инфраструктуры для «удаленки», мы остановились на варианте с рабочим пространством в облаке AWS — Amazon WorkSpaces, о котором и рассказываем.
Анатомия современной «удаленки»
Работа удаленно сегодня может ничем не отличаться по эффективности от работы в офисе, но при одном базовом условии. Рабочее пространство, среда, в которой оперирует сотрудник, должна обладать всеми привычными инструментами, используемыми сотрудниками для решения повседневных задач.
Сегодня это в подавляющем большинстве случаев – ИТ-сервисы, приложения, корпоративные системы и базы данных, доступ к которым обеспечивается удаленно по сети Интернет, FTP и другим протоколам. По большому счету весь переход на удаленный режим упирается в способность компании предоставить сотруднику доступ к его привычному рабочему столу в любой точке мира.
При этом, помимо грамотно составленного набора ИТ-инструментов и онлайн-решений, чрезвычайно важны скорость и качество связи, а также защищенность всех операций.
Все существующие сегодня решения по организации удаленной работы делятся на три базовых типа по своей функциональности:
Очевидный, но заслуживающий упоминания момент: при создании собственной конфигурации ИТ-решения для удаленки следует тщательно подходить к выбору дата-центров для размещения инфраструктуры. Не останавливайтесь на сравнении ЦОДов по ценам, проверьте их позиции в рейтингах, почитайте отзывы клиентов, поищите публикации о них в СМИ.
Что такое Amazon WorkSpaces
С учетом всех факторов, а также опыта тестирования различных инструментов из всех трех категорий, мы остановили свой выбор при развертывании ИТ-среды для удаленной офисной работы на решении Amazon WorkSpaces.
Amazon WorkSpaces – это удаленный рабочий стол в облаке Amazon, реализуемый по модели Desktop-as-a-Service – DaaS.
Сервис предоставляет доступ по требованию к рабочим столам в облаке и избавляет от необходимости покупать резервные компьютеры. Объемы вычислительных ресурсов, оперативной памяти и дискового пространства таких рабочих столов настраиваются в зависимости от задач компании и потребностей конкретных пользователей.
Amazon WorkSpaces можно использовать для развертывания рабочих столов на базе Windows или Linux. Сервис позволяет быстро масштабировать ресурсы и создавать буквально тысячи рабочих столов для сотрудников по всему миру.
Биллинг осуществляется за фактически использованные ресурсы, что позволяет оптимизировать расходы по сравнению с традиционными рабочими столами и локальными решениями с использованием инфраструктуры виртуальных рабочих столов (VDI). Конечно, для эффективного управления расходами важно уже на старте работы понимать, какие параметры виртуальных машин необходимы для ваших задач, чтобы не переплачивать за избыточные ресурсы.
Владеть и управлять аппаратным обеспечением, обновлять версии ОС и применять исправления, а также администрировать инфраструктуру виртуальных рабочих столов (VDI) – не нужно.
Как устроен сервис: нюансы и тонкости
Для управления информацией о пользователях, подключающихся к удаленным рабочим столам, WorkSpaces использует инструмент AWS Directory Service, который является службой AWS Managed Microsoft AD.
То есть, Amazon WorkSpaces не может работать без сервиса AWS Directory Service, и, следовательно, требуется оплата их обоих. Однако стоит отметить, что и Amazon WorkSpaces, и AWS Directory Service имеют бесплатные пакеты на срок до 1500 часов. Соответственно, есть возможность протестировать решение.
Кроме стандартных рабочих станций сервис Amazon WorkSpaces доступен с vGPU.
Этот пакет предлагает высокопроизводительный виртуальный рабочий стол. Он отлично подходит для разработчиков 3D-приложений и моделей, инженеров, использующих инструменты CAD, CAM или CAE.
Данный пакет доступен во всех регионах, где в настоящее время предлагается WorkSpaces, и может использоваться с любым устройством. Такое решение может стать альтернативой мощным офисным рабочим станциям в дизайн-студиях, которые в период изоляции оказалось невозможно доставить домой к сотрудникам, из-за чего компаниям пришлось либо организовывать закупку дорогостоящих ноутбуков, либо предлагать сотрудникам работу на личных устройствах.
Также, рабочие столы Amazon WorkSpaces с графическими процессорами можно использовать для анализа и визуализации данных. Так как мощности графического пакета находятся рядом с основными сервисами, такими как EC2, RDS, Amazon Redshift, S3 и Kinesis, можно проанализировать данные на сервере и затем визуально оформить результаты в смежном рабочем пространстве.
Эту комбинацию сервисов AWS можно использовать для создания приложений, разработка которых не была бы экономически эффективна при работе на обычных виртуальных машинах без использования графического процессора.
Как проходило тестирование
Мы протестировали сервис, проверив доступность удаленного рабочего стола из Интернета и с тестовой виртуальной машины в нашем облаке в Санкт-Петербурге.
1. Установили связность между нашей инфраструктурой в ЦОДе и нашим VPC (virtual private cloud) в AWS. Здесь все стандартно — настройка BGP, DCC, Virtual Gateway.
2. Определились с AD (Active Directory).
Согласно документации Amazon, можно использовать AD как управляемый Amazon, так и управляемый локально.
3. Для теста мы выбрали схему с AD, управляемым Amazon.
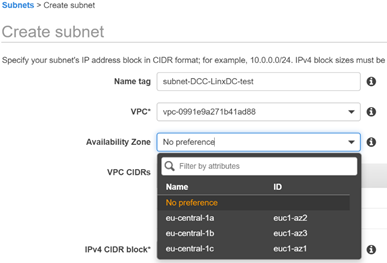
При такой схеме нужно иметь в виду, что на VPC должно быть, как минимум, две подсети из разных зон доступности. Это требование AWS, оно исходит из необходимости физически изолировать серверы AD друг от друга. Необходимо не меньше двух серверов.
Например, в регионе eu-central-1 (Frankfurt) есть три зоны доступности (Availability Zone) — eu-central-1a, eu-central-1b, eu-central-1c.
4. Для теста делаем один префикс в eu-central-1a, один префикс в eu-central-1b.
При создании подсети указываем AZ:
5. Две созданных нами подсети:

6. Создаем Active Directory и WorkSpace.
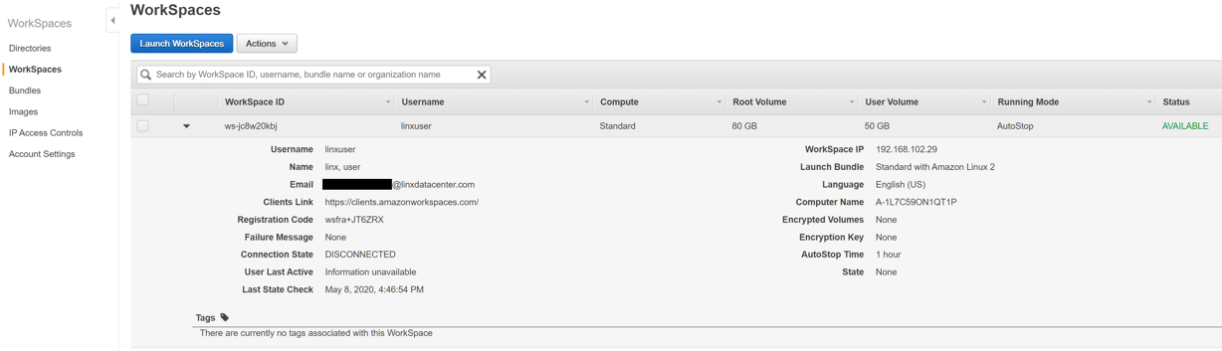
7. После настройки на указанную почту приходит письмо, в котором есть ссылка для смены пароля на рабочем столе и для скачивания Amazon WorkSpaces для разных платформ – Windows, Linux, MacOS и т. д.
8. Рабочий стол готов.
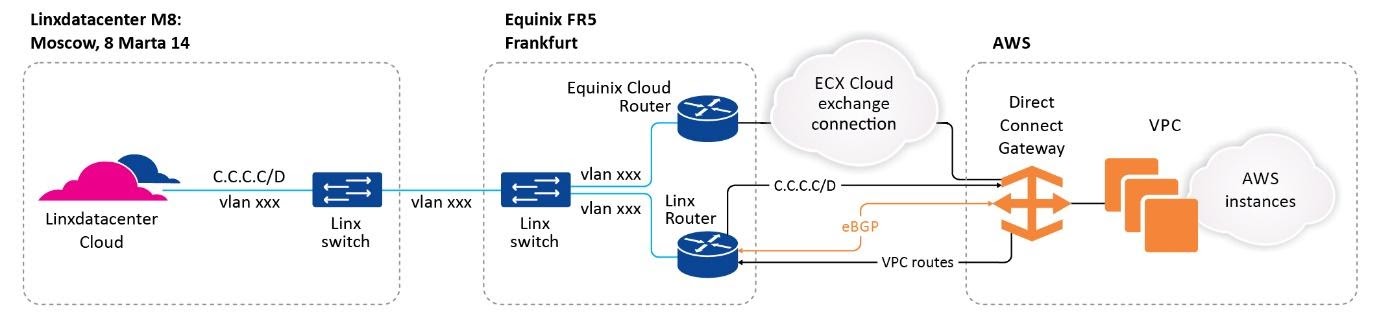
Прямое подключение к AWS
Для большинства компаний, имеющих собственные AD, будет интересна схема подключения с собственным AD. Для этого дополнительно необходимо настроить прямое выделенное соединение с AWS, через которое клиент может связать свой AD и ресурсы компании, расположенные локально, с облаком Amazon.
Схематично это выглядит так:

Нужно учитывать, что для стабильной работы сервиса задержка между хостом, с которого происходит подключение к рабочему столу, и локацией AWS, где расположен WorkSpaces, не должна превышать 100мс согласно рекомендации Amazon.
В нашем случае мы предлагаем клиентам соединение через Франкфурт — RTT (round-trip time) от Linxdatacenter в Москве и в Санкт-Петербурге до FR5 (точки присутствия на базе ЦОД Equinix во Франкфурте) составляет менее 40мс, что полностью удовлетворяет рекомендациям AWS.
Установка Amazon WorkSpaces на рабочую станцию
1. Устанавливаем приложение на рабочую станцию, с которой планируем подключаться.
2. Вводим Registration Code, который является идентификатором рабочего стола, и логин/пароль, указанные при создании WorkSpace.
3. Рабочий стол доступен на ноутбуке сотрудника.
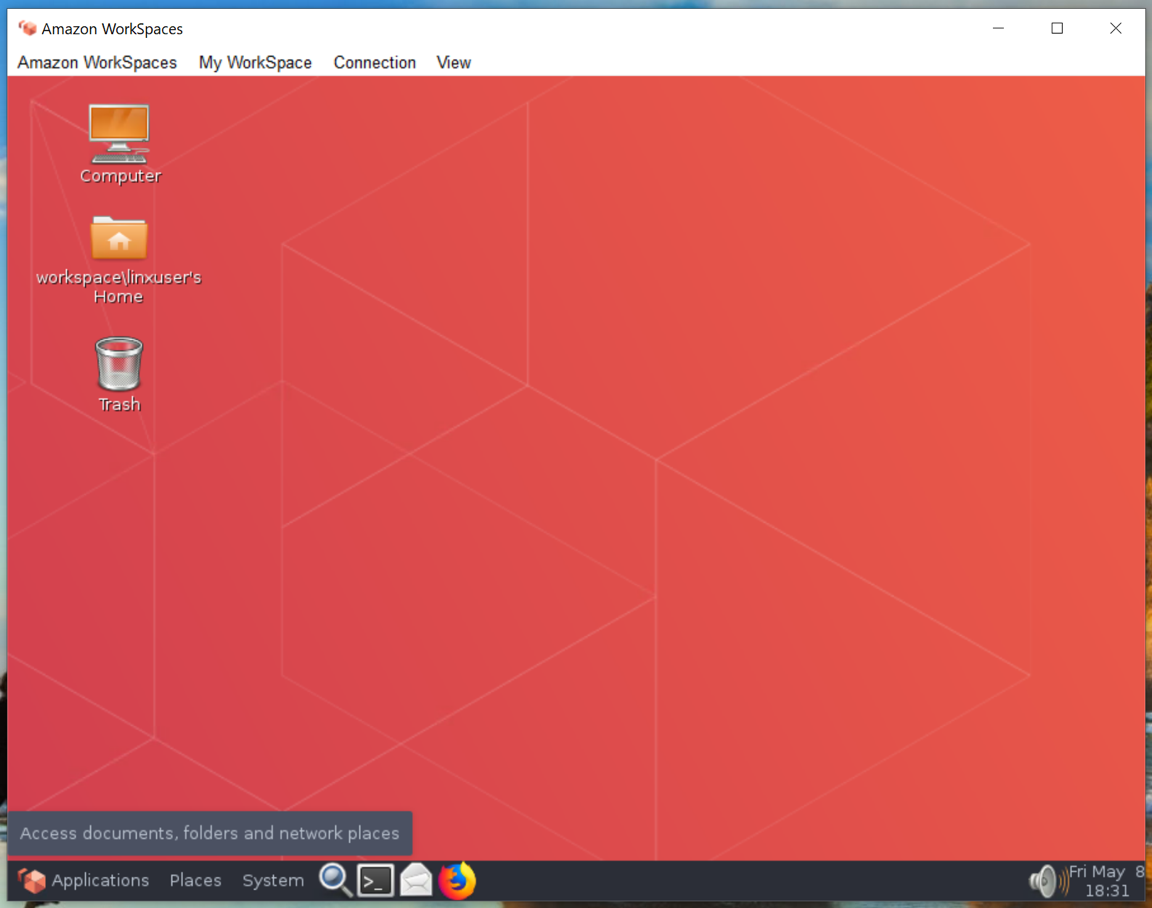
Скриншот с окном приложения Amazon WorkSpaces, подключенного к удаленному рабочему столу.
4. Теперь свяжем его с системами в компании. В нашем случае – на примере подключения к ВМ в облаке Linxdatacenter в Санкт-Петербурге.

5. В обратную сторону (ВМ в облаке в Санкт-Петербурге –> удаленный рабочий стол) связность также работает.
Развертывание и настройка пакета с vGPU не отличается от стандартной настройки. В момент, когда система предлагает выбрать вам пакет для развертывания, нужно найти нужный нам с графикой и выбрать его для установки.

Параметры минимального пакета с vGPU:
Развернули: что дальше?
Рабочие столы на Amazon WorkSpaces дают возможность мобильным и работающих удаленно сотрудникам использовать любые нужные для работы приложения через облачный рабочий стол, доступный из любой точки с подключением к сети Интернет.
Работает модель использование собственного устройства (BYOD): сервис поддерживает все стационарные ПК, ноутбуки Mac, iPad, Kindle Fire, планшеты на базе Android, Chromebook, а также браузеры Firefox и Chrome.
Если в компании возникают задачи тестирования софтверных новинок собственной разработки, рабочие столы Amazon WorkSpaces также решают эту задачу без повышения стоимости и необходимости хранить резервное оборудование. Самое главное: исходный код не будет храниться на устройствах разработчиков, а это дополнительная защита.
Еще один актуальный сценарий применения Amazon WorkSpaces – оперативное слияние нескольких ИТ-отделов для совместной работы по проекту, когда требуется оперативно синхронизировать работу большого числа специалистов.
Это все на сегодня — задавайте вопросы в комментариях.
P.S. Рекомендую посмотреть вот это видео по Amazon WorkSpaces.