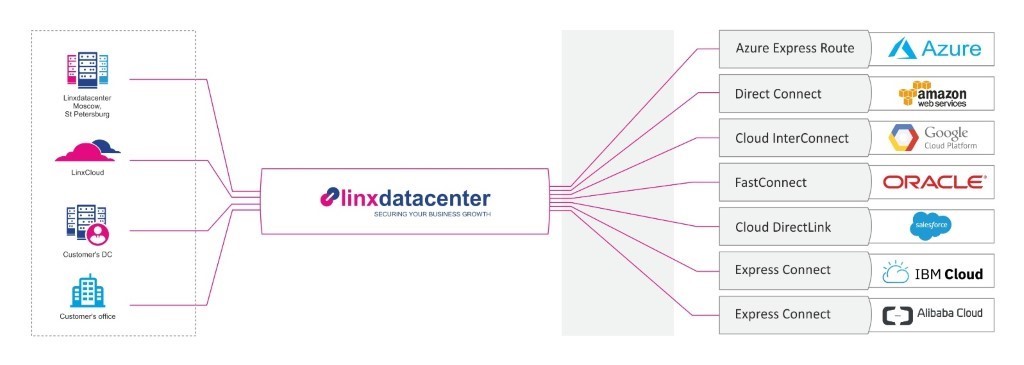
Подключение к глобальным облачным платформам с помощью прямого выделенного соединения
Ключевые преимущества
| Для ИТ-подразделений: |
Для Бизнеса:
|
- прямая связанность с глобальными облачными платформами;
- широкий выбор локаций подключения;
- выделенный канал с гарантированной скоростью передачи данных и сетевой задержкой;
- выполнение работ по настройке сети End-to-End;
- гибкое управление скоростью каналов связи в периоды миграций и пиковых нагрузок.
|
- снижение сроков и затрат на передачу данных во время миграции;
- договор на услуги по российскому законодательству;
- соблюдение требований по локализации данных согласно ФЗ-242;
- быстрая работа пользователей с глобальными облачными платформами;
- использование возможностей нескольких глобальных облачных платформ одновременно.
|
Применение
| Задача |
Требования |
Решение |
| Работа с несколькими облачными платформами |
- Возможность использования сервисов Microsoft, Google, Amazon с соблюдением закона ФЗ-242.
- Подписание договора на оказание услуг по требованиям законодательства РФ.
- Гарантированная связанность пользователей с глобальными облачными платформами.
|
- Доступ к запрошенным облачным сервисам в течение 48 часов.
- Предоставление услуги в полном соответствии требованиями законодательства РФ к документации: договор/счёт/акт.
- Выделенный гарантированный канал связи между инфраструктурой клиента и облачными площадками Microsoft, Google, Amazon.
- SLA на полосу пропускания канала и сетевую задержку.
|
| Разработка и интеграция программного обеспечения |
- Дополнительные вычислительные мощности и сервисы для тестирования и разработки ПО.
- Изолированная среда разработки от среды продуктивной эксплуатации.
- Надежная сетевая связность среды разработки с основной инфраструктурой.
|
- Использование готовой базы микросервисов от Microsoft, Google, Amazon для разработки ПО.
- Сокращение времени разработки и развёртывания ПО.
- Быстрое создание окружений с необходимой сетевой конфигурацией.
- Оплата только используемых мощностей по факту потребления.
- SLA на полосу пропускания канала и сетевую задержку.
|
| Организация новых и оптимизация действующих каналов связи |
- Временный канал/каналы связи для миграции больших объёмов данных в новую облачную локацию.
- Безопасное выделенное соединение с глобальными облачными платформами.
- Снижение затрат на обслуживание действующих каналов связи.
|
- Оперативное подключение по новым каналам: в течение 48 часов.
- Гибкое управление каналами связи через службу поддержки Linxdatacenter.
- Выделенный гарантированный канал связи между инфраструктурой клиента и облачными площадок Microsoft, Google, Amazon.
- SLA на полосу пропускания канала и сетевую задержку.
|

